Chad Rubin
June 16, 2026 · 13 min read
Operator notes by email
Short, opinionated takes on AI agents, Amazon PPC, pricing, and inventory. No fluff. About once a week.
Most Amazon AI-PPC software is wrapper tech. A vendor wraps a single GPT prompt in a UI, calls it proprietary intelligence, and charges $400 a month. The seller signs, runs it for 90 days, and ends up roughly where they started, because nothing about a wrapper actually understands their catalog, their margins, or their inventory position.
I have been on Amazon for 15 years. I built and sold Skubana. I have hired the agencies, run the spreadsheets, evaluated the tools. I have also been pitched by every flavor of Amazon software that exists, including the wrapper kind. The pattern is reliable: the demos look great, the dashboards look smart, and underneath the surface, the thing is not doing what the vendor says it does.
If you are evaluating an Amazon AI-PPC vendor right now, this is the operator's buyer-protection checklist. Five questions that separate real AI from wrapper AI. Every question has an answer to demand. Every answer has a red flag to watch for. And at the end of each section, I will tell you exactly how Profasee answers it, so you can compare any other vendor against a real baseline.
These questions also work for any Amazon vendor that claims AI, including repricers, demand planners, and listing optimizers. PPC is the easiest place to spot the wrappers, which is why I am writing this for PPC first.
## Key takeaways >- Most Amazon AI-PPC tools are wrappers around a single GPT prompt sold as proprietary intelligence. The 5 questions in this post are how you tell them apart.- Question 1 (coordination): does the agent share data with pricing, inventory, and listing decisions, or only optimize PPC in a silo?- Question 2 (data depth): can the agent see competitor keyword position, or only your own keywords?- Question 3 (reporting): how does the agent handle parent-child ASIN families in its analytics?- Question 4 (trust): what is the rollback path, the audit trail, and the failure-state behavior?- Question 5 (learning): does the agent learn from your catalog over time, or operate on a generic model that resets each session?
The gap between wrapper AI and real AI is not technical mystery. It is a product-marketing trick. The vendor builds a thin layer that takes Amazon data, passes it to a generic language model with a prompt, and shows the output in a dashboard. The math, the data structures, the feedback loops, and the cross-system coordination that would make it real AI are not there. The vendor knows you cannot tell from the demo.
Real AI for Amazon requires three things the wrappers do not have. First, proprietary data on your specific catalog, sales, margins, and history. Second, vertical depth in how Amazon actually works (campaign structures, fee math, algorithm behavior). Third, feedback loops that learn from outcomes and compound intelligence over time. Wrappers have a clever prompt and a dashboard. That is not the same thing.
From reading to action
If the framework above sounds familiar, your Amazon account is probably carrying the same drag. Apply and we will show what Marko, Oracle, and Bruno would change in your first week.

Ran a 7-figure Amazon brand for a decade. Founded Skubana (acquired). Co-founded Prosper Show. 15+ years on Amazon.
Join the brands that replaced agencies and tools with AI employees.
The five questions below test for those three properties without requiring you to be a machine-learning engineer to evaluate the answer.
What to ask: "If Bruno (or whatever your demand planner is named) flags an inventory risk on an ASIN, does the PPC agent automatically pause spend on that ASIN? If Oracle (or your pricing agent) changes a price, does the PPC agent adjust bids to reflect the new margin?"
Why this matters: PPC decisions made without inventory and margin context are the most expensive blind spots on Amazon. Running ads on an ASIN that is about to stock out wastes spend on traffic that does not convert. Running ads on a price point that just dropped wastes spend by overpaying for clicks the margin can no longer support. A PPC tool that does not see those other signals is optimizing in a vacuum.
The red flag: "We integrate with your inventory tool" or "We pull data from your ERP." Integration is not coordination. Pulling a CSV does not equal an agent making decisions across functions. If the vendor describes the integration as a data import, the answer is no.
The right answer: the agent and the pricing agent and the demand-planning agent share a state, see each other's decisions, and react in real time. When inventory hits the reorder threshold, ads pause. When the price changes, bids adjust. When listing quality drops, spend reduces until the listing is fixed. This is what coordination actually means.
How Profasee answers it: Marko (the PPC agent) shares state with Oracle (pricing), Bruno (demand planning), and Brett (catalog auditor). When Bruno flags a stockout risk on an ASIN, Marko pauses ad spend on that ASIN automatically. When Oracle changes a price, Marko adjusts bids to match the new margin. When Brett finds a listing issue hurting conversion, Marko reduces spend on that ASIN until it is fixed. That coordination is the whole point of the platform. The AI operating system post walks the full architecture.
What to ask: "If I give you an ASIN, can you tell me my organic and sponsored keyword position for every keyword that matters? Can you tell me the same for my top three competitors? What is the data source, and how often does it refresh?"
Why this matters: Bid decisions made without rank context are guesses. If you are ranking organic position 3 for a keyword, you should not be paying top-of-search rates for the sponsored slot. If you are ranking position 47 and your competitor is at 5, the bid strategy is different. A PPC agent that cannot see rank cannot make those decisions intelligently.
The red flag: "We optimize against your own ACoS data" or "We use Search Term reports." Those are inputs, not rank data. ACoS does not tell you where you rank. Search Term reports tell you what converted, not where you sit on the SERP.
The right answer: the agent looks at keyword rank, combines it with Search Query Performance (SQP) click and conversion share, and turns that into recommendations like increase spend, trim spend, review the listing, or abandon the keyword.
How Profasee answers it: Marko tracks organic and sponsored keyword position at the ASIN and keyword level when the rank provider is configured. For your own products, Marko already uses this in rank-push workflows: it looks at keyword rank, combines it with SQP click and conversion share, and turns that into specific recommendations. For competitor positions, the architecture supports top-competitor-ASIN plus competitor organic and sponsored rank through the position-intel layer, with the exact competitor rank scanning dependent on the controlled SERP provider being enabled. Without that provider, there is still competitive visibility through SQP and placement proxies, but those get described as proxy signals, not exact competitor rank scans. We are honest about which is which. (Source: Profasee product Q&A and internal product team.)
What to ask: "I have 200 ASINs and most of them sit under parent ASIN structures with multiple variations. When I look at performance, can I see it rolled up at the parent level, broken out by child, and filter at either level? What about when one child is in stock and the rest are running low?"
Why this matters: Parent-child ASIN families are how every real catalog is structured on Amazon. A PPC tool that treats every child ASIN as a flat row in a spreadsheet is unusable on a 200-SKU catalog. The reporting needs to handle the hierarchy, and the actions need to respect it. Pausing spend on a parent because one child is out of stock is different from pausing spend only on the stockout-risk child while keeping the rest running.
The red flag: "We pull each child ASIN as its own row" or "You can search for the parent ASIN to find its children." That is a flat list, not a tree. If the answer involves CSV exports to make sense of the hierarchy, the answer is no.
The right answer: the catalog UI supports parent-child ASIN families with a grouped default view, parents expand to show child variations, child rows carry their own ASIN-level data (inventory, pricing, COGS, margin, Buy Box), and filters work at the right level for the decision being made.
How Profasee answers it: the catalog UI supports parent-child ASIN families. The default view is grouped: parent ASINs and standalone ASINs show as top-level rows, and parent rows expand to show child variations. Child rows carry their own ASIN, SKU, variation value, inventory, pricing, COGS, margin, Buy Box, goal, and workflow status. Current catalog filters are applied at the row-and-query level before grouping, which means you are primarily filtering top-level parent or standalone rows, then expanding to see child variations. Stats avoid double-counting parent-only containers, so catalog counts are based on sellable SKUs rather than artificial parent rows. (Source: Profasee product Q&A and internal product team.)
What to ask: "If your AI raises a bid 40 percent overnight and the ACoS triples by morning, what is the path to undo it? Is there an audit trail of every action with the reasoning behind it? What is the agent's behavior when it gets confused or sees data it does not understand?"
Why this matters: Every AI vendor will tell you the AI does not make wrong decisions. Every one of them is lying. AI makes wrong decisions all the time. The question is not whether, the question is whether you can see them, undo them, and trust the agent's failure state. A vendor that cannot answer the rollback question is a vendor whose AI you do not actually control.
The red flag: "Our AI is trained on millions of data points so wrong decisions are very rare" or "You can change the rules in the dashboard if you want." Neither of those is a rollback. Both are deflections.
The right answer: every action has an audit trail showing what changed, when, why, and on whose decision (agent or human). Every action has a one-click undo within a defined window. The default failure state of the agent is "do nothing", not "guess." Hard guardrails (spend caps, price floors, bid limits) cannot be exceeded by the agent under any condition.
How Profasee answers it: Ultra starts in observe mode. It shows what it would do before touching anything. You set rules, limits, and approval thresholds. Every action has a reason, an audit trail, and a one-click undo within 72 hours. Hard guardrails (spend caps, price floors, bid limits) are absolute and cannot be exceeded. No-Fly Zones let you lock specific ASINs, keywords, or time windows from any agent change. The failure state is "agents do nothing", not "agents guess." The full safety and guardrails page and the DIY AI automation risks post cover this in detail.
What to ask: "If I run your AI for six months, does it get better at my specific catalog? Where does that learning live? If I cancel and resubscribe, does the agent remember anything about my account, or does it start fresh?"
Why this matters: This question separates wrapper AI from real AI more cleanly than any other. A wrapper feeds your data into a generic model each session and shows you the output. There is no memory. There is no compound intelligence. The "AI" that ran for you on day 90 is the same AI that ran for you on day 1, because nothing was learned in between. A real AI builds a model of your specific catalog, customers, and competitive landscape, and gets sharper with every cycle.
The red flag: "Our model is trained on data from all our customers, so it benefits from the network effect" or "We use the latest GPT model, so it is always learning." Both of those are misdirections. Training data from other customers does not mean the agent knows your account. A newer LLM does not mean an agent that knows your catalog.
The right answer: the agent maintains a per-account memory of your catalog, your campaigns, your historical responses to ad spend and pricing changes, your competitive landscape, and your business outcomes. That memory compounds. The agent that runs for you on day 180 should be measurably smarter than the one that ran on day 1, and the vendor should be able to show you specifically what got smarter.
How Profasee answers it: the Performance Memory Flywheel is the architecture for this. Ultra learns your catalog (ASIN-level history, fee math, variation structure), your customers (behavioral and demographic patterns), and your competitive landscape (top competitors per ASIN, their ranking and pricing behavior). The flywheel compounds: every cycle the agents make decisions, observe outcomes, and update the per-account model. After 90 days the agents know your account meaningfully better than on day one, and we can show you the difference in decision quality. If you cancel and come back, the memory persists, you do not start from zero.
There is one more question that does not fit cleanly under AI mechanics but matters more than the other five combined: how does the pricing model work?
If the vendor charges per seat, the incentive is misaligned. They want more logins, not more profit. If the vendor charges per ad-spend percentage, they are incentivized to grow your spend, not your margin. The right pricing model for an Amazon AI-PPC vendor is per agent or per outcome, where the vendor only wins if your business wins.
This is one of the reasons single-function PPC tools fall behind operating-system-style platforms. The single-function tool optimizes spend efficiency in a silo and gets paid on logins. The operating-system platform optimizes profit across functions and gets paid on the value created. Different incentives produce different outcomes.
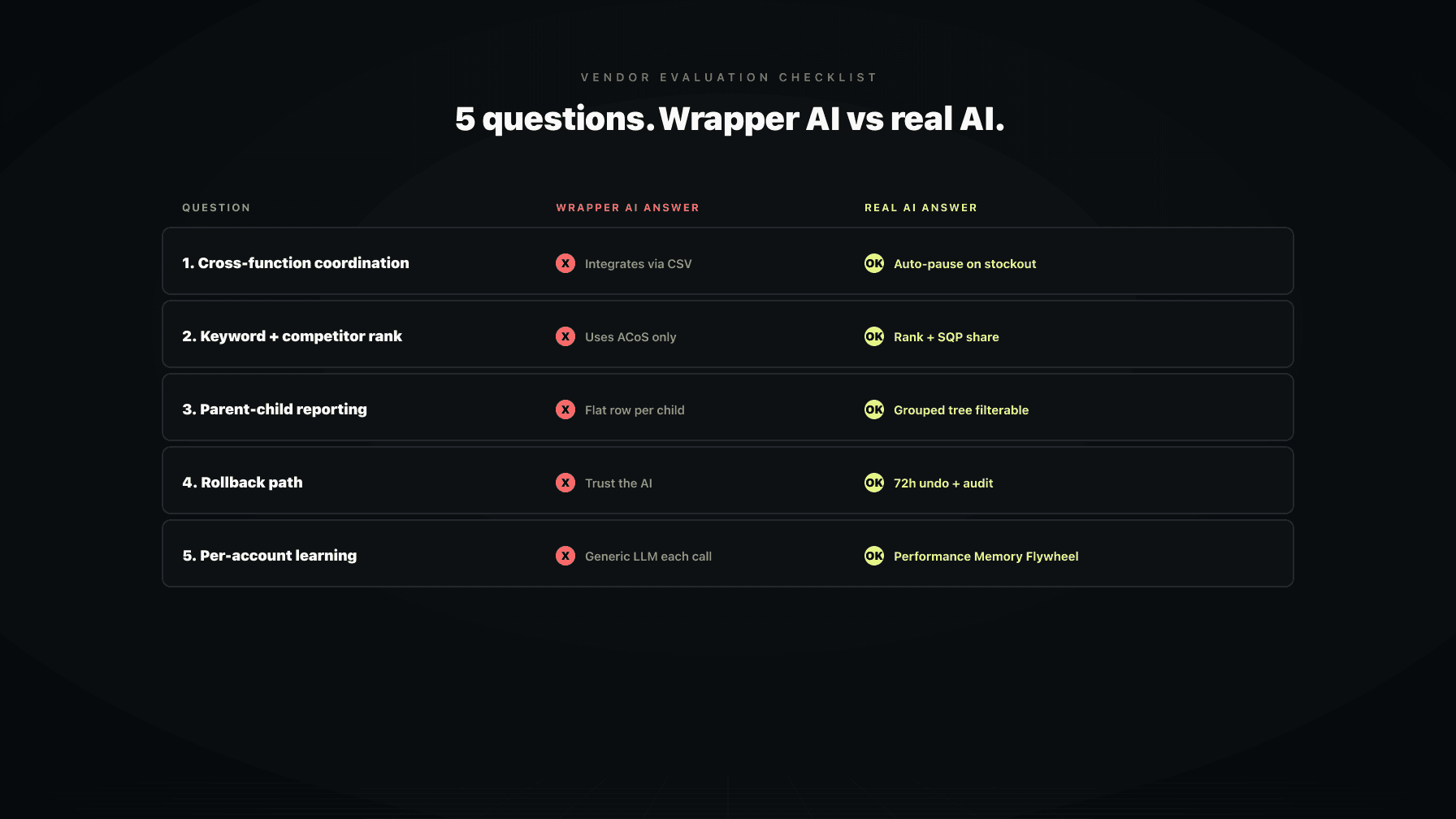
Question | Wrapper AI answer | Real AI answer |
|---|---|---|
Cross-function coordination | "We integrate with your other tools" | "Pricing changes trigger bid adjustments automatically" |
Keyword and competitor rank | "We use Search Term reports" | "Organic and sponsored rank by ASIN, plus competitor data via position-intel layer" |
Parent-child reporting | "Each child shows as its own row" | "Grouped tree view with filter at either level" |
Rollback path | "Our AI rarely makes mistakes" | "One-click undo within 72 hours, every action audited" |
Per-account learning | "We train on all our customer data" | "Per-account Performance Memory Flywheel that compounds" |
If a vendor cannot answer four of those five in the right column, the AI is wrapper-tier and the price is too high regardless of what the demo showed.
The fastest way to verify a vendor's answers is to put their AI on your account in observe mode for 30 days. Read-only, no actions, just recommendations. Every recommendation gets a reason. At the end of 30 days you have a record of every decision the AI would have made on your account, what the reason was, and whether the recommendation was right.
If the vendor does not offer an observe mode, that is the loudest red flag of all. It means they either cannot run their AI safely on a real account or they are scared of what 30 days of side-by-side comparison would show. Either way, you have your answer.
If they do offer it, run two vendors at once. The contrast will be obvious within 14 days.
A PPC agency is humans making decisions on a schedule, usually weekly or monthly, charging $10K+/month. An AI PPC software runs continuously, makes decisions in seconds, and charges a fraction of agency rates. The trade-off used to be that agencies brought strategic context that software could not. The agency advantage is shrinking fast as AI software starts to coordinate across functions and learn per account. The PPC agency alternative post covers this transition.
Ask for the rollback path and the per-account learning architecture. Rule-based automation has a list of conditions and actions you can see in a dashboard. Real AI has a memory that compounds and decisions that change as the agent learns. Rule-based tools are reliable for narrow problems and limited by the rules. AI tools are unreliable for narrow problems if poorly trained and exceptional for broad problems if properly trained. Most "AI" PPC software is actually rule-based with a marketing layer on top.
Three common models. Per seat (the legacy SaaS model, misaligned with profit). Percentage of ad spend (incentivizes spend growth, misaligned with margin). Per agent or per outcome (the model Profasee uses, aligned with profit). The right pricing model is the one where the vendor only wins if your business wins.
Yes, in observe mode. Run the AI alongside the agency for 60 to 90 days. Compare what the AI recommended to what the agency did. If the AI recommendations are consistently better, the agency is the next thing to cut. If the agency is materially better, you have your answer for now. Either way you learn something. Most operators who run this test end up cutting the agency within 90 days. The DIY AI automation risks post covers how to run the comparison safely.
Run it in observe mode. Make no changes to your current setup. Compare the AI's recommended actions against what you (or your agency) actually did. Calculate the would-be profit impact of each recommendation. At the end of 30 days you have a real data set on whether the AI's decisions were better, worse, or roughly the same as what was actually happening. Then decide.
It depends on what "small" means. Under $30K/month in revenue, the ROI math is usually not there yet. Above $50K/month with 20+ SKUs, AI PPC software is increasingly the rational choice over manual management or a $10K/month agency. The break-even is the cost of the software versus the cost of the time saved plus the profit gained from better decisions.
Three reasons. One: most of it is wrapper AI, not real AI, and the wrappers cannot do what real AI can do. Two: most of it optimizes PPC in a silo, without seeing pricing, inventory, or listing context, which means it is optimizing the wrong number. Three: most of it does not learn from your account over time, so the decisions on day 90 are no better than day 1. The vendors that solve those three problems are the ones that work in practice.
If you take one thing from this post, take this: ask the five questions, demand specific answers, and run an observe-mode test before you commit. Every vendor will say yes to a sales call. Only a few will hold up under the five questions. Even fewer will hold up under 30 days of side-by-side observation against your current setup.
If you want to see how Profasee answers all five, apply here and we will put Marko on your account in observe mode for 30 days. No commitment. Read-only. At the end you decide.