Chad Rubin
June 6, 2026 · 15 min read
Operator notes by email
Short, opinionated takes on AI agents, Amazon PPC, pricing, and inventory. No fluff. About once a week.
There are two ways to ruin an AI agent on your Amazon account, and they sit at opposite ends of the same dial.
The first is to make it ask you about everything. Every bid change, every price nudge, every keyword harvest lands in your inbox waiting for a thumbs up. Within a week you stop reading the notifications. Within two weeks you approve in batches without looking. The agent is technically supervised and practically unsupervised. You bought automation and you got a second job answering questions.
The second is to make it ask you about nothing. You flip it to fully autonomous, you go on vacation, and you come back to a hero ASIN that got repriced below floor during a buy-box fight, a branded campaign that doubled its budget chasing a competitor, and a new launch the agent throttled because it read three days of soft data as a real decline. Each action made sense in isolation. The damage was in what nobody flagged.
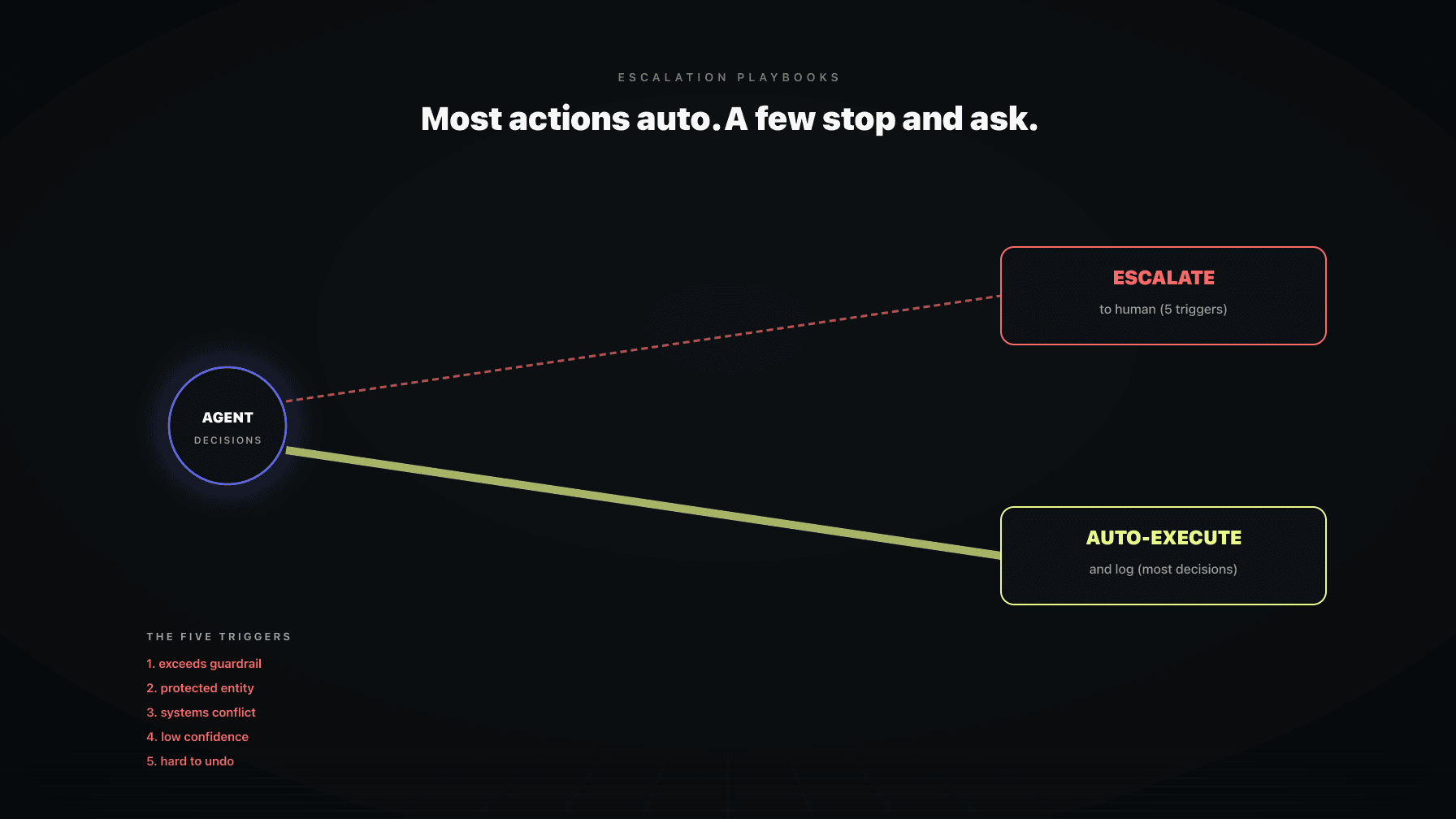
The interesting work is not building a smarter agent. It is deciding which decisions the agent owns outright and which ones it has to hand back to you. That is escalation design, and it is the difference between an agent you trust and an agent you disable.
This is a playbook for it: five triggers that should stop an agent and route the decision to a human, one rule for everything else, the two failure modes you hit if you get the dial wrong, and how the rules should tighten or loosen as your trust changes. None of this requires you to understand the model. It requires you to know your own business.
People evaluate AI agents on the wrong axis. They ask how good the recommendations are. That is the easy part. Most agents that touch ads, pricing, and inventory produce reasonable recommendations most of the time. The hard part is the small percentage of decisions where the agent is wrong, or unsure, or technically right in a way that costs you money you cannot recover.
From reading to action
If the framework above sounds familiar, your Amazon account is probably carrying the same drag. Apply and we will show what Marko, Oracle, and Bruno would change in your first week.

Ran a 7-figure Amazon brand for a decade. Founded Skubana (acquired). Co-founded Prosper Show. 15+ years on Amazon.
Join the brands that replaced agencies and tools with AI employees.
Escalation is how you handle that small percentage without supervising the large one. It is a routing rule. For every decision the agent is about to make, it asks one question: does this belong to me, or to the human. If the answer is human, it stops and waits. If the answer is the agent, it acts and writes a log entry.
Get the routing right and the agent is genuinely useful. The boring 95 percent runs itself and the 5 percent that needs your judgment actually gets it, because you are not buried under approvals for things that never needed you. The five triggers below are the routing rules I would build for any agent on a real account. They are not exotic. They are the things a good operator already pays attention to, written down as conditions a system can check.
The first trigger is the simplest. You set numeric limits, and crossing one stops the agent.
A guardrail is a hard bound. The agent can move a bid up to 30 percent in a day, drop a price to a floor and no lower, spend up to a daily ad budget. Those are limits it operates inside without asking. The escalation rule sits at the edge of that limit: when the agent's best decision would require crossing the bound, it does not cross. It stops and asks.
Here is the part people get backwards. The threshold is not the point at which the agent acts. It is the point at which it hands the decision to you. If the data genuinely supports a 45 percent bid increase and your cap is 30 percent, the right behavior is not to silently cap at 30 and move on. It is to execute up to 30 if that is safe, then surface the rest: I wanted to go to 45, your bound is 30, here is why, do you want to override.
Set these thresholds where a reasonable operator would want to be told. Most price moves inside a normal band are routine. A move that crosses a margin floor, blows past a percentage swing, or breaches a MAP agreement is not. That is the line. The threshold encodes how much variance you are comfortable with the agent owning by itself.
The second trigger is about what the decision touches, not how big it is.
Some entities carry more risk than their size suggests. A hero ASIN that drives a third of your revenue is not a normal SKU. A branded campaign defending your trademark is not a normal campaign. A new launch in its first 60 days is fragile in a way a mature listing is not. A small mistake on any of these costs more than a large mistake on a long-tail product nobody buys.
So you tag them. You mark a set of entities as protected, and any decision touching one escalates regardless of size. A two percent price change on a random SKU auto-executes. The same change on your hero ASIN routes to you, because the downside of being wrong there is asymmetric.
This is the trigger that catches the failure from the intro, where every individual action looked fine. The agent repricing a hero ASIN during a buy-box fight was making a locally correct call. But a hero ASIN is exactly where you want a human looking before the move lands, even when it looks reasonable, because the cost of a wrong reprice on your biggest earner is not symmetric with the cost on a small one.
Protected status is a business judgment, not a model output. You decide what is fragile. The agent respects the tag.
The third trigger lives in the gap between tools, and it is the one most setups miss entirely.
Your pricing agent wants to cut price to clear stalled velocity. Your inventory agent sees the same SKU low on cover and wants to hold price to ration the remaining units until the next shipment lands. Each is right inside its own silo. Together they are about to do something dumb: cut the price on a unit you are about to run out of, accelerate the stockout, and hand the buy box to a competitor right before you go dark.
No single agent sees this. The pricing agent does not know about the inbound shipment delay. The inventory agent does not know velocity is stalling. The conflict only exists when you look at both at once, and most account damage lives exactly there, in between the silos.
The rule is: when two systems would act on the same entity in opposite directions inside a short window, neither acts. The conflict surfaces to a human with both positions laid out, and you decide whether to clear the stall with a cut or protect the cover by holding. That is a judgment call about what matters more this week, and it is yours.
I covered this gap in the piece on cross-system guardrails. The short version: per-tool rules protect each tool from itself and are blind to each other by design. Conflict escalation is the layer that protects the business from the interaction effects.
The fourth trigger is about the agent's own uncertainty, and a good agent knows when it does not know.
A SKU's sales jump 40 percent over three days. Is that a real trend you should ride with more inventory and more ad spend, or is it noise from a one-time bulk order, a competitor stockout, or a holiday weekend that reverts next week? At three days of data the honest answer is the agent cannot tell. The signal is real but the interpretation is a coin flip.
A bad agent treats the spike as a trend, ramps spend and reorders, and watches demand revert while you sit on overstock and a blown budget. A good agent recognizes the confidence is low, holds the aggressive move, and escalates: I see a 40 percent lift, it could be a trend or noise, here is what I would do under each reading, which is it.
The mechanism is a confidence score on the decision, with a floor below which the agent escalates instead of acting. The floor depends on reversibility. A low-confidence ad bid is cheap to reverse, so the agent can act and watch. A low-confidence reorder of 90 days of inventory is expensive to reverse, so the same confidence level should escalate. The less reversible the action, the higher the confidence the agent should need before acting alone.
This is also where you avoid the opposite mistake: treating every wobble as a decision. Most short-term variance is noise, and the agent should let it pass. Low confidence on a meaningful, hard-to-reverse move escalates. Low confidence on a trivial, reversible one just gets logged and watched.
The fifth trigger is the one I would never compromise on, because reversibility is the whole game.
Some actions you can undo in a click. A bid change reverts. A price moves back. Those are cheap mistakes, and an agent should be allowed to make them and learn, because the cost of being wrong is a few hours of slightly worse performance.
Other actions you cannot take back. A purchase order is committed cash and committed weeks of lead time. A long-term storage decision plays out over months. A coupon or deal submitted into Amazon's machinery is hard to claw back once it is live. A listing change that tanks your indexing can take weeks to recover. These are the kind of thing where being wrong costs you real money over a real timeline.
So the rule is: the harder a decision is to undo, the more it should escalate, independent of how confident the agent is or how small the number looks. A confident, well-supported, modest reorder still escalates if reorders are committed cash in your business. The agent can prepare it, lay out the math, and tell you exactly what it would do. It just does not pull the trigger on irreversible spend by itself.
Patience is cheap here. Re-stabilizing after a committed mistake is not. This trigger keeps a fast agent from making a slow, expensive error you spend the next quarter cleaning up.
Now the part people forget, which is that the four-out-of-five decisions that trip none of these triggers should never reach you at all.
A bid adjustment inside your daily bound, on a non-protected campaign, with no conflicting system, decent confidence, and trivially reversible: the agent should just do it. No notification, no approval queue. It acts and writes a line to the log. That is the default for routine work, and it has to be the default or the whole thing collapses into the drowning failure below.
Logging is what makes auto-execution safe. The point of auto-execute is that the right thing happens whether or not you are awake. The point of the log is that you can verify it happened the way you would have wanted, on your schedule, not theirs. Every auto-executed action gets a timestamped entry with what changed, the data behind it, and the before-and-after state. You read the log during your daily review, not in real time.
The mental model is a good employee. You do not want your media buyer asking permission to lower a bid by eight percent on a campaign that is overspending. You want them to do it and tell you. You do want them to walk into your office before placing a six-figure purchase order. The triggers draw that line for a machine instead of a person.
If your agent is asking you about routine, reversible, in-bounds actions, it is misconfigured. That is not caution. That is noise, and noise is what gets your real escalations ignored.
This is the failure I see more often, because it feels responsible. You set escalation tight. Everything routes to you. You tell yourself you are staying in control.
What actually happens: the queue fills with dozens of routine decisions a day. The first week you read them carefully. The second week you skim. By the third you are clicking approve in batches, because the queue is full of bid nudges and minor price moves that were obviously fine and you have learned the agent is almost always right. You are now rubber-stamping. You have all the burden of supervision and none of the benefit, because you are not reading the thing you approve.
The damage shows up the day a real escalation lands in the same queue as the noise. A genuine conflict, a real protected-entity decision, something that needed your eyes. It gets batch-approved with everything else, because you trained yourself to clear the queue, not read it. The over-sensitive setup did not make you safer. It buried your one important decision under fifty unimportant ones.
The fix is to move routine decisions out of the queue and into the log. The queue should be small enough that every item in it genuinely deserves a human. If you are approving more than a handful of things a day, your triggers are too sensitive and you should loosen them, not power through. A queue you actually read beats a queue you clear.
The opposite failure feels efficient right up until it is not. You set escalation loose, the agent handles almost everything, and for a while it is great. The account runs itself. You stop checking.
Then one of the five triggers fires in real life and the agent does not stop, because you never told it to. It reprices the hero ASIN below floor in a buy-box fight. It rides a three-day spike into overstock. It commits a purchase order on a misread trend. It defends a branded campaign into a budget the keyword did not deserve. None of these were caught because every guardrail was set wide, nothing was tagged protected, and nothing was watching for conflicts.
This failure is quieter than the first, which makes it worse. Drowning in approvals is annoying and obvious; you feel it every day. Overreach is invisible until the damage is done. You find out when you read the P&L, not when the decision was made.
The fix is to wire up all five triggers before you loosen anything. Loose escalation is fine for reversible, unprotected, in-bounds, high-confidence decisions. It is dangerous the moment a real exception has no rule to catch it. Loosen on the cheap, reversible categories. Keep the irreversible and protected ones tight no matter how good the agent has been.
Escalation is not a setting you configure once. It moves with your trust, in both directions, and the signal for moving it is boring agreement.
When the agent is new to a category, escalate aggressively. You want to see its reasoning on a wide range of decisions, including ones it should obviously own, because that is how you learn whether to trust it. This maps to the early rungs of the trust ladder: observe, then approve, then let it act inside narrow bounds. The queue is wide on purpose at the start.
You loosen when you stop disagreeing. If you have approved a hundred bid decisions in a row and rejected one, the queue is teaching you nothing except that you are a bottleneck. That single-digit rejection rate is the signal to pull those decisions out of the queue and let the agent own them, with logging. Boring agreement is readiness. The absence of disagreement is the signal, not exciting wins.
Loosen at different speeds, because reversibility differs. Ads are cheap to reverse, so a PPC agent earns autonomy fast. Pricing is medium, because a bad price has a tail. Inventory is slow, because reorders are committed cash and a wrong call sits on your shelf for months. The same trust history graduates an ad decision long before a purchase order.
And tighten when something breaks. If an auto-executed decision turns out wrong, that category goes back into the queue until you understand why and trust it again. Tightening is not punishment. It is information. The dial moves both ways, and a setup that only ever loosens is heading for the overreach failure.
This is the model we built Profasee around, because it is the only one that survives contact with a real account.
The agents handle routine work without asking. The PPC manager adjusts bids, harvests keywords, and shifts budget inside the bounds you set, and most of that never reaches you. The pricing agent moves prices inside your floor and ceiling on velocity and competitive signal, and the normal moves auto-execute. That is the 95 percent, and it runs itself with a log behind it.
The five triggers route to an approval queue in Mission Control. Cross a guardrail threshold, touch a protected entity, conflict with another system, fall below a confidence floor on a meaningful move, or attempt something irreversible, and the decision stops and waits. The queue is deliberately small, because routine work never enters it. When you sit down for your daily review or weekly cadence, it holds the handful of decisions that actually wanted your judgment, not fifty you would have approved blind.
Everything else is logged. Every auto-executed action carries a timestamped entry you can audit on your own schedule, which is how you verify the agents did what you would have done without standing over them. And the bounds move with your trust, tightening when something breaks and loosening as the rejection rate falls into single digits, category by category, at the speed reversibility allows. That is the difference between an agent you supervise into the ground and one you actually run a business with.
An agent should escalate when a decision trips one of five triggers: it would cross a guardrail threshold, it touches a protected entity like a hero ASIN or branded campaign, it conflicts with what another system wants to do, it has low confidence on a meaningful move, or it is irreversible or expensive to undo. Decisions that trip none of those should auto-execute and log instead of asking. The goal is for the things that reach you to be the things that genuinely need your judgment.
Move routine decisions out of the approval queue and into a log. If the agent is asking permission for in-bounds, reversible, non-protected, high-confidence actions, it is misconfigured and should just do those and tell you afterward. Reserve the queue for the five escalation triggers. A queue full of obvious approvals trains you to rubber-stamp, which means your real escalations get cleared without a second look. Smaller queue, fuller attention.
A protected entity is anything where the cost of a mistake is bigger than its size suggests: a hero ASIN that drives a large share of revenue, a branded campaign defending your trademark, or a new launch in its fragile first weeks. You tag these, and any decision touching one escalates regardless of how small the change is. The downside of being wrong on a hero ASIN is not symmetric with being wrong on a long-tail SKU, so it gets a human's eyes before the move lands.
When one system wants to cut price to clear velocity and another wants to hold to ration low stock, neither should act alone. The conflict escalates to a human with both positions laid out, and you decide which matters more this week. No single agent can see this gap because each is correct inside its own silo. This is a cross-system escalation, and it catches the kind of damage that lives in between tools rather than inside any one of them.
Only when the move is meaningful and hard to reverse. A three-day spike that could be a trend or noise should escalate if the agent's response would be a large reorder or a big spend ramp, because being wrong there is expensive. The same low confidence on a cheap, reversible bid tweak should just be acted on and watched. Confidence and reversibility work together: the less reversible the action, the higher the confidence the agent should need before acting alone.
They loosen as you stop disagreeing. When you have approved a long run of decisions in a category and rejected almost none, that single-digit rejection rate is the signal to pull those decisions out of the queue and let the agent own them with logging. You loosen faster on reversible categories like ads, slower on pricing, and slowest on inventory, where reorders are committed cash. And you tighten again whenever an auto-executed decision turns out wrong, until you understand why.
Guardrails are hard limits the agent cannot cross at all: a price floor, a daily budget cap, a maximum bid swing. Escalation is the routing rule that decides which decisions reach you instead of being handled automatically. They work together. The guardrail sets the bound, and the escalation rule fires when a decision would push against that bound, handing it to you rather than silently capping it. You need both: limits the agent obeys, and exceptions it brings to you.


