Chad Rubin
May 2, 2026 · Updated May 11, 2026 · 12 min read
Operator notes by email
Short, opinionated takes on AI agents, Amazon PPC, pricing, and inventory. No fluff. About once a week.

I have watched a lot of Amazon sellers buy an AI tool, flip it to full autonomous on day one, and then quietly turn the whole thing off four weeks later after a bad week of ACoS or a price war they did not start. The tool was fine. The adoption was the problem.
The demo you saw was on clean data. A curated account. Tidy SKU naming, accurate cost of goods, no orphan campaigns from 2021. Your live account is messier than that. So is mine. So is every account I have ever poked around in over the last decade.
The fix is not to slow down. The fix is to climb a ladder. There is a real path from "watch only" to "handle it" and it has five rungs. Sellers who skip rungs blow up. Sellers who climb in order keep their margin.
This post lays out the trust ladder I use with our own AI employees at Profasee, and the one I would use even if I were buying somebody else's stack.
Most of the AI conversation right now is about model quality. Which model is smarter, which one reasons better. That is a fun debate but it is the wrong frame for an Amazon operator.
What actually decides whether an AI agent helps or hurts your P&L is not the model. It is the operating mode you have it in, relative to how clean your data is. A perfect agent in autonomous mode on a messy account will still tank you. A pretty good agent in approve mode on the same account will save you money, because you are catching the dumb stuff before it ships.
The trust ladder exists because the data inside an Amazon account is never as clean as a vendor demo. SKUs with wrong cost basis. Old A/B tests still running. Restocked variants that share an ASIN with a discontinued one. The agent does not know any of this on day one. You do. The ladder is the structure that lets you teach the agent what you know without paying for the lesson in lost margin.
From reading to action
If the framework above sounds familiar, your Amazon account is probably carrying the same drag. Apply and we will show what Marko, Oracle, and Bruno would change in your first week.

Ran a 7-figure Amazon brand for a decade. Founded Skubana (acquired). Co-founded Prosper Show. 15+ years on Amazon.
Join the brands that replaced agencies and tools with AI employees.
In phase 1, the agent reads your account and reports what it sees. It does not propose changes. It does not make changes. It just narrates.
This sounds boring. It is supposed to be boring. The point of observe mode is to find out whether the agent has a coherent picture of your business at all. Does it correctly identify your top SKUs by contribution margin, not just revenue? Does it know which campaigns are branded versus non-branded? Does it know your real cost of goods, not the placeholder cost from when you onboarded?
You stay in observe mode until the agent's narration of your account matches your own mental model. If it is calling a campaign "high performing" and you know that campaign cannibalizes your branded traffic, the agent is missing context. Fix the context before you climb.
The common mistake here is to rush. Observe feels useless because nothing is happening. But observe is where you find the data hygiene problems that would have caused a disaster in autonomous mode.
Once the agent's narration is accurate, you move it to recommend mode. Now it proposes specific actions. Lower this bid. Pause this keyword. Lift this price by $1.50. Add this negative.
You do not approve them one by one. You approve them in batches, on a cadence. Once a day is plenty. You read the batch, reject the ones that look wrong, approve the rest. The agent learns from the rejections, either through explicit feedback or through the patterns you set in your guardrails.
The output of phase 2 is a rejection rate. Track it. Week one, you might reject 30 to 40 percent. That is normal. Week three, if you are still rejecting 40 percent, something is wrong with the agent's framing. Either it does not understand a constraint you have, or it is over-confident on a noisy signal. Stay in phase 2 and fix that.
When your rejection rate settles into the single digits and the rejections feel like edge cases rather than fundamental disagreements, you are ready for phase 3.
Phase 3 looks similar to phase 2 from the outside but it feels different. The default expectation is now approve. The agent sends you a daily digest. You skim it. You approve almost all of it. You reject the rare item that looks off.
The reason this is its own phase is that your relationship to the queue changes. In phase 2 you are scrutinizing each item. In phase 3 you are scanning for outliers. That cognitive shift matters. You are training yourself to trust the agent's defaults and intervene only when something pattern-breaks.
This is also where you start measuring time saved. Phase 3 should compress to a 10 or 15 minute morning review for most agent types. If it is taking longer, your guardrails are too loose and the agent is throwing you too many edge cases. Tighten before moving up.
Phase 4 is where the agent acts without per-action approval. You set guardrails. Bid changes capped at a percentage per cycle. Price changes bounded by floor and ceiling. Ad spend capped per campaign per day. Inside the box, the agent acts. Outside the box, it pauses and asks.
You review weekly. You look at outcomes, not actions. Did ACoS hold? Did margin hold? Did any single SKU swing more than X percent? Were any guardrails hit, and why?
Phase 4 is what most sellers think they are buying when they buy AI. They are right that this is where time savings show up. They are wrong that this is where you start. The previous three phases earn you the right to be here without it costing you.
Phase 5 is for agents that have run cleanly in phase 4 for at least a quarter. The cadence shifts from weekly to monthly. You stop reviewing actions. You review strategy. Are we still optimizing for the right objective? Has the category shifted? Has our pricing power changed? Should we redefine the guardrails?
Phase 5 does not mean the agent is unsupervised. The supervision has moved up a level. You are no longer auditing the work. You are auditing the goal.
A lot of sellers never reach phase 5, and that is fine. There is nothing wrong with running in phase 4 forever. Phase 5 is a posture you earn for one or two agents while the others stay at lower rungs.
Each phase catches a different category of problem, and you cannot catch phase 3 problems while you are still in phase 1. The phases are not redundant.
In observe you catch data problems. Wrong cost of goods. Mislabeled campaigns. SKUs the agent does not realize are seasonal. Stockout-driven anomalies treated as performance signal.
In recommend you catch judgment problems. The agent proposes things that are technically correct but strategically wrong. Pause our highest-volume non-branded campaign for a bad ACoS week, ignoring that it feeds organic rank. Drop a price below where we are willing to go. Not data bugs. Missing-strategy bugs.
In approve you catch edge-case problems. The big stuff is right. The small stuff occasionally goes sideways. A competitor launched a coupon and the agent is reading the price drop as a permanent shift. A two-week-old ASIN is being treated like a mature one.
In autonomous within guardrails you catch guardrail problems. The agent hits the same wall over and over and you realize the guardrail itself is wrong. Or the agent's behavior right at the edge is suboptimal. You do not see these in lower phases because the guardrails are not really in play yet.
In autonomous with monthly review you catch strategic drift. The agent is doing exactly what you told it to do, and what you told it to do is no longer what the business needs.
If you skip phases, you do not skip the bugs. They hit you all at once, in production, while the agent is moving real money.
Every operator has felt the pull. The agent has been right four times in a row. You are tired of approving. The dashboard looks great. Why not turn it loose.
I have done this. It almost always punishes me. The pattern is consistent. The agent has been right on a quiet stretch. The stretch ends. Something unusual happens in the category, in your inventory position, or in your competitor set. The agent does the wrong thing fast, because it is now in autonomous mode, and you do not catch it because you stopped looking.
The cost of climbing one rung at a time is patience. The cost of skipping is asymmetric. A bad week of bids costs a few percent of margin. A bad week of pricing costs more, because price changes ripple into the buy box and competitor responses. A bad week of inventory costs you for a quarter, because you are now overstocked or understocked and the system takes time to recover. Patience is cheap. Re-stabilizing is not.
A lot of sellers want to put the whole stack on the same rung at the same time. Do not. Different agents mature at different speeds, because the consequences of a bad action differ.
PPC graduates fastest. Actions are reversible inside a few hours. A bad bid is a bad bid for one day. The feedback loop is tight. You can run a PPC agent in phase 4 with reasonable confidence after a few weeks of phase 2 and 3.
Pricing graduates in the middle. A bad price action is reversible, but second-order effects are not always reversible cleanly. You drop a price, lose buy box from a competitor who matched, raise it back up, and do not always recover the position. The feedback loop is days, not hours. Plan on more time in phase 2 and 3 for pricing than for PPC. (See /blog/amazon-pricing-strategy/.)
Inventory graduates slowest. A bad reorder is a multi-month problem. You cannot un-buy a container of stock. Inventory agents should sit in phase 2 or 3 for a long time, and many sellers keep them there permanently.
The PPC agent in phase 4, the pricing agent in phase 3, the inventory agent in phase 2 is not an immature stack. That is a thoughtful operator.
Sellers ask me how they know when to climb. The honest answer is that the signal is boring.
You are ready to move up when you stop disagreeing with the agent. Not when it has a great week. Not when the dashboard turns green. When you go two or three weeks approving its calls and your rejections feel like edge cases rather than fundamental disagreements.
What to watch:
If those are true, climb. If not, stay. The discomfort of climbing too early is much higher than the discomfort of climbing too late.
Climbing is not one-way. Sometimes an agent that was running cleanly in phase 4 starts making weirder calls. Maybe the category shifted. Maybe a variant launch confused its priors. Maybe a guardrail you set six months ago no longer fits.
When that happens, you roll back. Drop from phase 4 to phase 3. Reinstate the daily digest. Watch for a couple of weeks. Figure out what changed. Adjust guardrails or context. Climb again when the agreement is back.
This should be one click. If your AI tool makes it hard to roll back, that is a tool problem. Operating modes are dials, not commitments. You should be able to drop a single agent one or two rungs without affecting the others, without losing history.
Rollback is not failure. It is a normal part of the operating rhythm. The sellers best at this roll back early and often, rather than refuse because they think it means they were wrong.
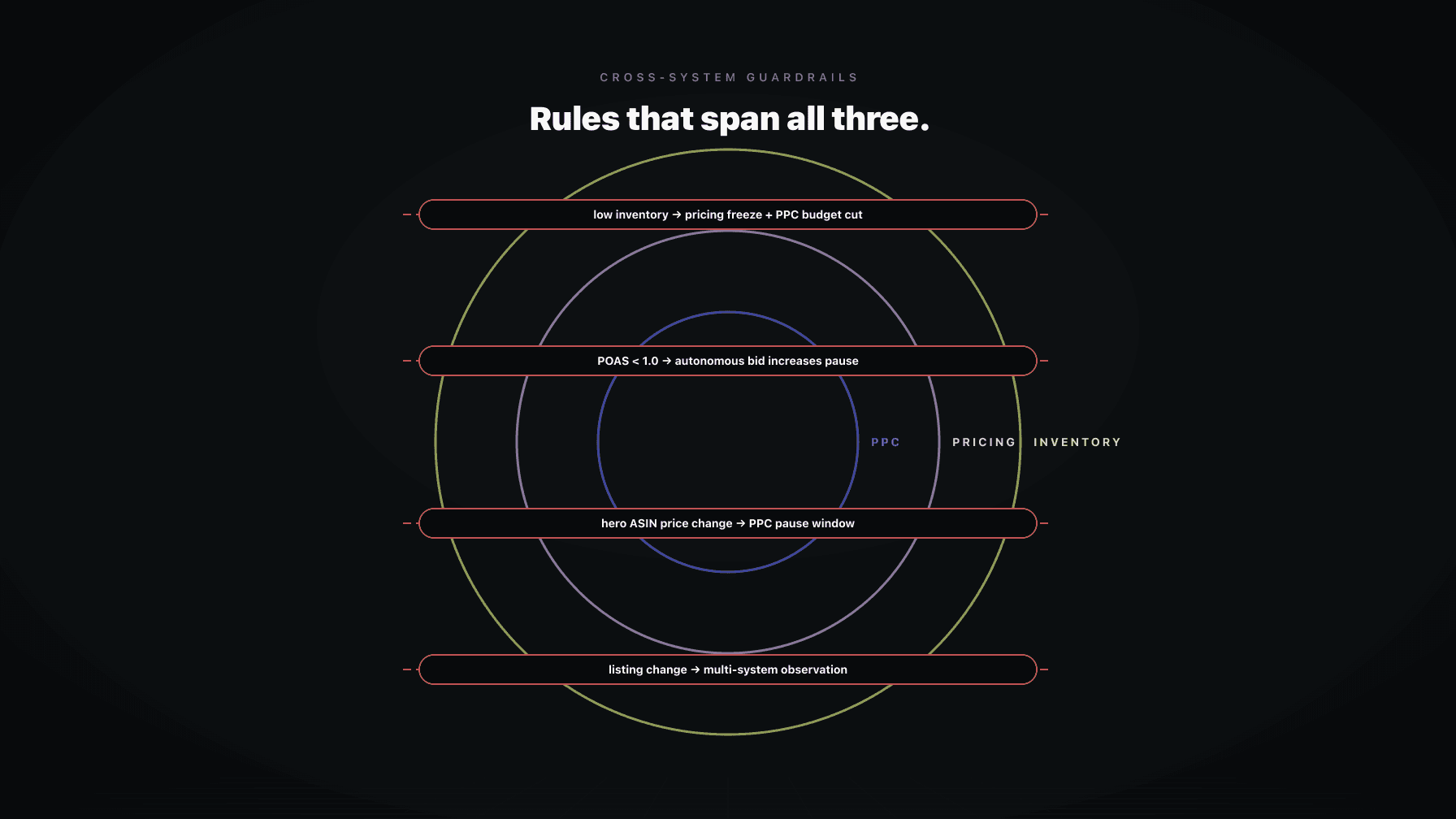
We built Profasee Ultra around this ladder because we lived through the wrong version of AI adoption ourselves. Every AI employee has its own operating mode setting, and they are independent.
In Mission Control, you can set Marko (the PPC manager) to autonomous within guardrails while keeping Oracle (the pricing agent) in approve mode. Bruno (creative) in recommend while Brett (deals and promotions) sits in observe. Each agent climbs at its own pace.
The pending approvals queue surfaces every action that needs review for agents currently in recommend or approve mode. It collapses similar items so you are not approving the same kind of bid change a hundred times. The audit log records every action every agent took, in every mode, with the reasoning. That log is what makes rollback safe.
Rollback is a single setting per agent. You drop Marko from autonomous back to recommend, and within minutes the next set of actions is sitting in your approval queue instead of going live. The other agents are unaffected.
The point is to make the right adoption pattern the easy one. Sellers who climb the ladder properly should have the better experience inside the tool, and sellers who try to skip should bump into a little friction that makes them reconsider.
No. The demo was on clean data. Your account is not as clean, no matter how disciplined you are. Start in observe mode so the agent can read your account and you can verify it has the right picture. Move to recommend once the narration matches your understanding. Skipping straight to autonomous is the most common reason AI adoption fails on Amazon, because the agent is moving real money before you have caught the data problems.
For PPC, expect four to eight weeks of disciplined climbing if your data is reasonably clean. For pricing, eight to twelve weeks. For inventory, a quarter or longer, and many sellers keep inventory agents in approve mode permanently. Think of it as a signal, not a calendar. You graduate when your rejection rate has been in the single digits for at least two weeks and the rejections feel like edge cases.
In observe, the agent reads your account and reports what it sees, but proposes no actions. The point is to verify the agent has the right picture before it suggests changes. In recommend, the agent proposes specific actions on a cadence (lower this bid, lift this price, pause this keyword) and you approve in batches. Observe is agreement on facts. Recommend is agreement on judgment.
Yes, and you should. PPC agents graduate fastest because actions are reversible within hours. Pricing graduates in the middle because second-order effects on the buy box take days. Inventory graduates slowest because a bad reorder is a multi-month problem. A mature stack typically has PPC in phase 4, pricing in phase 3, and inventory in phase 2 or 3. That is matching the operating mode to the reversibility of the action.
The bugs do not skip with you. Observe catches data problems. Recommend catches judgment problems. Approve catches edge-case problems. Autonomous catches guardrail problems. Skip phases, and all of those bugs hit in production at once while the agent is moving real money. You save a few weeks of approving items and lose months recovering.
Watch for boring agreement, not exciting wins. The signal is that you have stopped meaningfully disagreeing with the agent for two or three weeks. Rejection rate in the single digits. Rejections are narrow and specific. The approval queue feels like a chore rather than a useful checkpoint. When all of those are true at once, climb. If only some are true, stay.
Rollback should be one click per agent. You drop from autonomous back to approve or recommend, the next batch lands in your approval queue instead of going live, and the other agents are unaffected. You do not lose history. Watch the digest for a couple of weeks, figure out what changed (often a category shift, a variant launch, or a stale guardrail), adjust, and climb again. Rollback is a normal part of the operating rhythm.