Chad Rubin
May 9, 2026 · Updated May 11, 2026 · 12 min read
Operator notes by email
Short, opinionated takes on AI agents, Amazon PPC, pricing, and inventory. No fluff. About once a week.
Most sellers I talk to think guardrails are a feature inside their bidder, or a checkbox inside their repricer. Set the floor, the ceiling, the max bid, walk away. That works until it doesn't. The day the repricer drops a hero ASIN to a new low because a competitor is testing a coupon, while the bidder is still pushing aggressive bids on the same ASIN, while the demand planner is sending a reorder PO based on the spike that's about to happen, is the day you find out per-tool guardrails are necessary but not sufficient.
I've been a 7-figure Amazon brand owner for over a decade. Every time I've seen automation embarrass an account, the root cause has been the same. A rule existed inside one system. It did not exist across systems. The tools were each operating safely on their own terms, and the business still got hurt because nothing was looking at the full picture.
This post is not a rerun of the PPC guardrails post. That one covered the tactical layer: budget caps, bid ceilings, dayparting, negative keyword discipline, the things you set inside the ad console. Read it. Set those. They are the floor. This post is about the layer above that floor: cross-system guardrails, rules that span pricing AND PPC AND inventory at the same time. The trust layer. The thing that lets you let AI agents run autonomously without losing sleep.
Per-tool guardrails are real protection. Your repricer floor stops a price collapse. Your bidder ceiling stops a runaway CPC. Your inventory tool's reorder lead time stops you from ordering the day before a stockout. Each rule works. Each rule is also blind to the other two.
The repricer does not know that ad spend on this SKU just doubled because the bidder hit a search term that was about to convert. The bidder does not know that the price just dropped, which is going to spike conversion rate, which means the bid that was right ten minutes ago is wrong now. The forecast tool does not know that the price drop plus the bid push are about to consume the safety stock you were planning to hold for Prime Day.
From reading to action
If the framework above sounds familiar, your Amazon account is probably carrying the same drag. Apply and we will show what Marko, Oracle, and Bruno would change in your first week.

Ran a 7-figure Amazon brand for a decade. Founded Skubana (acquired). Co-founded Prosper Show. 15+ years on Amazon.
Join the brands that replaced agencies and tools with AI employees.
Each tool is doing its job. The job they cannot do is coordinate. Coordination is not a feature inside any of those tools. It is a property of the system that holds them. If you only have per-tool guardrails, you have safety inside each silo and risk in between the silos. Most account damage lives in between the silos.
Here are the failure shapes that single-tool guardrails do not catch. None are exotic. All are common.
The price chase. A competitor drops price for a few hours. Your repricer follows. Your bidder, unaware, keeps spending at the old conversion assumptions. CPC stays high, conversion stays normal, but margin per order has collapsed. POAS goes negative on every click. The repricer is fine. The bidder is fine. The account is bleeding.
The stockout sprint. Forecast tool sees demand rising and flags a reorder. Bidder sees the same demand and pushes harder. Repricer sees velocity and starts walking price up. All three tools are individually correct. Together, they are sprinting you toward a stockout six weeks before the next inbound shipment lands.
The listing change blackout. You update the title or main image. Conversion rate drops by a third for 72 hours while Amazon recalibrates. Your bidder reads the new conversion rate as truth and lowers bids. Your repricer reads the lower velocity as a signal to drop price. Two days later you've cut bids and price on a product that was fine.
The silent reallocation. One ASIN gets featured in a deal. Spend shifts to it. Other ASINs lose budget. Conversions drop on the starved ASINs. Repricer sees lower velocity, drops price. Bidder sees lower conversion, drops bids further. Spiral.
These are weekly occurrences in any non-trivial catalog. None get caught by guardrails inside a single tool because none are caused by a single tool.
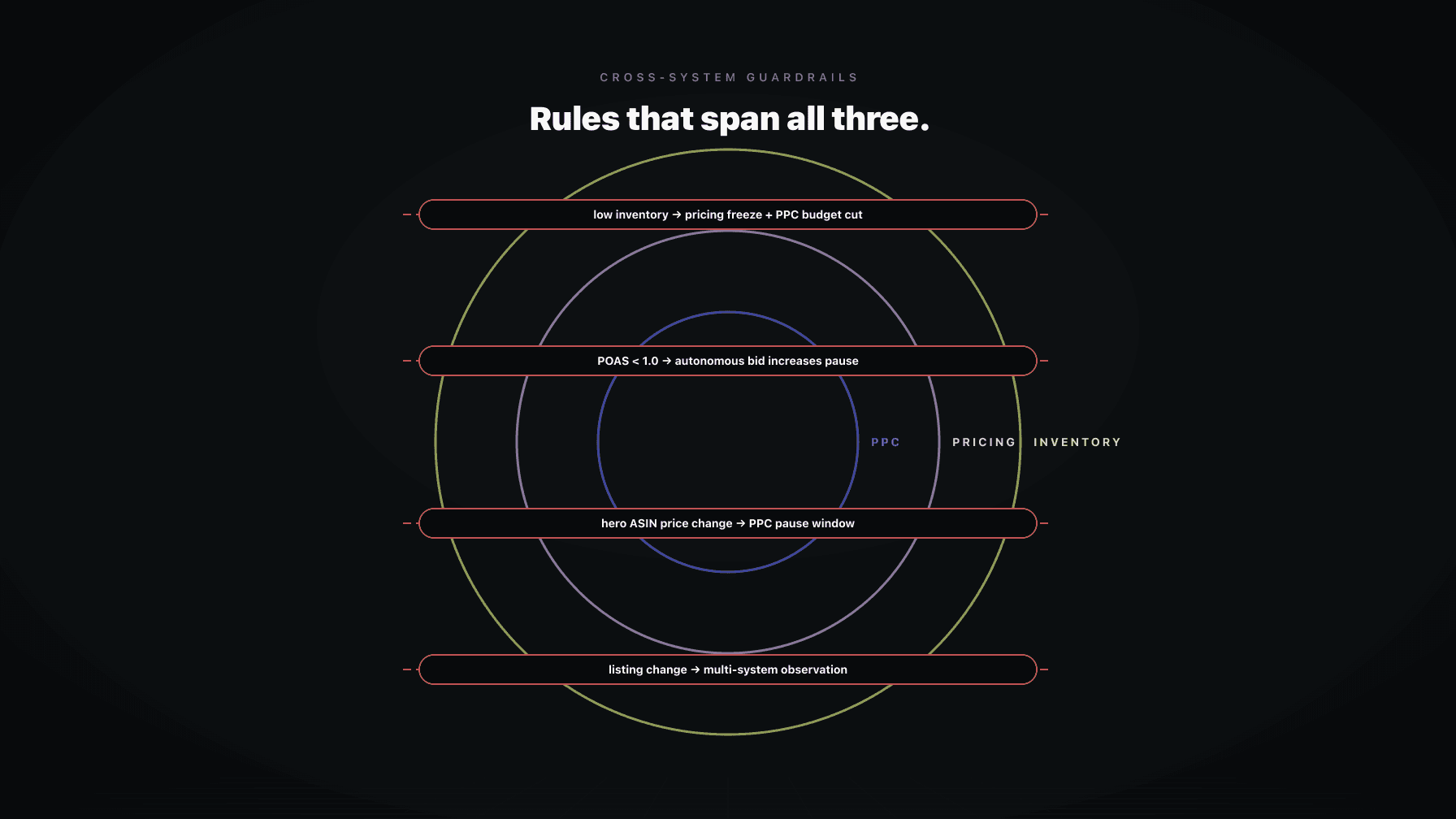
Rule: when units on hand on an ASIN drop below a defined cover threshold (for example, 21 days of forward-looking demand), pricing is no longer allowed to discount that ASIN. The repricer can hold or raise. It cannot drop.
Cross-system because the trigger is inventory and the action is pricing. Neither tool, on its own, has both halves.
What it prevents: discounting yourself into a stockout. Selling the last 200 units 18% cheaper than you needed to. Burning marketplace momentum on inventory you cannot replace for six weeks.
What you set: cover threshold, action (freeze, raise, or alert), and which catalog tier it applies to.
Rule: if account-wide POAS for the trailing 48 hours falls below a threshold you set, the system pauses new aggressive bid increases and new price drops, account wide, until a human reviews.
Cross-system because POAS is a function of price (margin per order) and PPC (cost per order) together. It is the only metric that exposes when the two systems are misaligned. The repricer sees ACOS as input, not output. The bidder sees margin as a static input, not a variable.
What it prevents: the slow bleed week. Everything looks fine in each individual dashboard, the spend report is normal, the price report is normal, and the P&L at the end of the month shows you lost money on accelerating revenue.
What you set: account-wide POAS floor, time window, and what "pause" actually means.
For the metric itself, see target POAS vs ACOS.
Rule: when the price of a hero ASIN moves by more than X% (say 5%) in either direction, all aggressive PPC actions on that ASIN pause for Y hours (say 12 to 24) so the conversion rate signal can stabilize.
Cross-system because the trigger is a pricing event and the action is a PPC action. CVR and ACOS readings are unreliable for the first half-day after a price change. If your bidder reacts to those readings, you get whipsaw.
What it prevents: the bidder over-correcting on stale assumptions. Bid increases that read as profitable on the old price and stop being profitable on the new one.
What you set: percent threshold, pause window, which ASINs are "hero."
Rule: when forecasted days of cover for an ASIN crosses below a defined floor (for example, 14 days), the system reduces or pauses ad spend on that ASIN automatically. Tiered: 14 days = halve spend, 7 days = pause non-branded, 3 days = pause all paid traffic.
Cross-system because the forecast signal triggers a PPC action. Neither tool owns both ends of that chain.
What it prevents: paying for clicks on units you are about to run out of. Paying for clicks that go to the buy box when the buy box is about to disappear.
What you set: cover thresholds, the action at each tier, and whether branded defense stays on.
This is the cleanest example of why these rules cannot live inside a single tool. The bidder cannot reliably see your inventory horizon. The forecast tool cannot reliably push ad changes. For the bidder side of this, see how pricing reduces Amazon ACOS and why PPC bids fail without pricing.
Rule: when a listing materially changes (title, main image, bullets, A+, variant structure, category), the system enters a 72 to 96 hour observation period. During that window, no automated price drops, no automated bid drops, no rebalances based on velocity. Only conservative actions allowed.
Cross-system because a listing event triggers freezes across pricing, PPC, and forecast inputs simultaneously. The tool that did the thing is catalog. The tools that need to react are all three.
What it prevents: cascading wrong reactions to a temporary CVR dip. Cutting bids on a product that is about to recover. Dropping price on a product whose CVR drop is artificial.
What you set: which change types qualify, observation window length, which actions are blocked.
Rule: total daily PPC spend across the account is capped. When the cap is approaching, instead of pausing campaigns alphabetically, the system reallocates remaining budget toward whichever campaigns are returning the best POAS in the trailing 24 hours.
Cross-system because the cap is a PPC concept, but the redistribution rule is profitability-aware (pricing) and inventory-aware (don't pour money into ASINs that are about to stock out, see guardrail 4).
What it prevents: hitting your daily cap and watching the system pause your best returning campaigns because they happened to spend fastest.
What you set: account daily cap, redistribution metric (POAS over ACOS), and the time window.
Rule: every cross-system action above a defined materiality threshold (dollar impact, percent of category spend, or hero ASIN involvement) gets logged with reasoning and surfaced for human review. A human can override any rule. The override is also logged with its reasoning.
Cross-system because the audit log is the meta-rule. It does not prevent any one event. It prevents the worst version of the other six rules from going wrong silently.
What it prevents: not knowing why something happened. Discovering on a Monday that something fired on a Saturday and you cannot reconstruct the chain of decisions.
What you set: materiality threshold, who gets notified, the review interface, the override audit trail.
The AI agent adoption trust ladder is built on this guardrail. Without an audit log, there is no trust ladder, only blind faith.
People assume guardrails are a feature you turn on inside Helium or Pacvue or your repricer. Per-tool, they are. Cross-system, they are not, and they cannot be. Three reasons.
First, no single tool sees all three data streams. Your bidder does not have your true unit economics or your inbound shipment dates. Your repricer does not have your search term-level CVR. Your forecast tool does not have your real-time ad spend. Vendors will tell you their tool "integrates" the others, and what they mean is they pull a number on a delay, not that they run on the live signal.
Second, no single tool's incentive structure is right for cross-system safety. A bidder vendor's incentive is to spend more efficiently. A repricer vendor's incentive is to win the buy box. A forecast vendor's incentive is to nail the inbound. None of them lose if the other three are misaligned. The vendor who loses is you.
Third, even if a single tool could see all three streams, the rules need to be expressed in the operator's language. "If days of cover drops below 14, halve ad spend" is an operator rule. It is a business rule. It belongs in the layer where the operator works. That layer is the operating system, the thing that sits above the agents. See the AI operating system for Amazon brands for the broader frame.
Most sellers carry these rules in their head. The first cross-system guardrail you write down is the one that earns you the right to stop being on call. A good encoding has six fields per rule.
Trigger: what signal fires this rule. Be specific. "POAS account-wide for trailing 48 hours below 1.4" is a trigger. "Things look bad" is not.
Condition: optional refinements. "Only on hero ASINs." "Only between 9am and 9pm Eastern."
Action: what happens. Pause aggressive moves. Freeze the price floor. Reduce ad spend by 50%. Notify a human.
Scope: which agents, which catalog tier, which time window the action applies for.
Override path: who can override and how, and how the override is logged.
Review cadence: how often you look at how often the rule fired and whether it should be tightened or loosened.
Six fields. Seven rules. Forty-two cells. That is your trust layer in a single page.
You do not deploy a cross-system guardrail and walk away. You test it. Three modes, in order.
Shadow mode. The rule is active but its action is "log only." It evaluates every event and writes what it would have done. You read the log for two weeks. Did it fire when you expected? Were the would-be actions sensible?
Partial mode. Enable the action on a subset (one campaign, one brand, one tier of the catalog). Watch. Compare against the part of the catalog still running without the rule.
Account-wide. Enable. Set a reminder to review in seven days, then thirty.
The mistake most operators make is going from no rule to account-wide enforcement overnight. That is how you find out a rule was wrong by watching it cut your top campaign in half on a Tuesday. Shadow mode is cheap. Use it.
In Ultra, these rules live in Mission Control. Not inside an individual agent's settings page. Mission Control is the operator's view. It is the one place where every cross-system rule is editable, visible, and audit logged.
Each guardrail can span Marko (PPC), Oracle (pricing), Bruno (demand), and Brett (catalog). When a rule fires, every agent involved logs the event with full reasoning. You can replay it. You can challenge it. You can override it. The override is also logged.
The seven guardrails above ship as templates. You can run them as defaults, or you can edit the trigger, condition, action, scope, and override path on each one. Every change to a guardrail is itself logged, so you can see who changed what when, and what fired before vs after the change.
The point is not the dashboard. The point is that the rules live above the agents, not inside them. That is what makes them work.
If your current setup is a repricer plus a bidder plus a forecast tool plus a spreadsheet that ties them together, the spreadsheet is your trust layer right now, and it does not scale. See if Ultra is a fit at the apply page, or read more on the broader system at Amazon pricing strategy and pricing PPC inventory coordination.
A cross-system guardrail is a rule whose trigger lives in one system (say inventory) and whose action lives in another system (say PPC, or pricing). It cannot be encoded inside a single tool because no single tool has both halves of the rule. It lives in the operating system layer above the agents.
A per-tool setting (a bid ceiling, a price floor, a max budget) protects one tool from itself. It is necessary. A cross-system guardrail protects the business from the interaction effects between tools. They work at different levels of the stack. You need both. The per-tool layer is the floor. The cross-system layer is the ceiling.
The POAS account-wide circuit breaker (guardrail 2). It is the cheapest to implement, it surfaces the most expensive failure mode (silent margin bleed across pricing and PPC together), and it teaches you more about your account in two weeks than any dashboard. Set it in shadow mode first. Watch what would have fired.
Partially. You can write them down, set up alerting that triggers on cross-system conditions, and use a human review step for the action. That is the manual version. It works at small scale. It does not scale to a large catalog with sub-hourly events. At that point you need the rules running in software, not in a Slack channel.
Three modes. Shadow mode (rule logs what it would have done). Partial mode (rule active on a subset of the catalog). Account-wide. Spend two weeks in shadow before going partial. Spend two more weeks in partial before going account-wide. Almost every guardrail mistake gets caught in shadow mode if you actually read the log.
The action runs. The event gets logged with full reasoning. A notification goes out per the rule's notification settings. When you wake up, you see what fired, why, what changed, and you can override or accept. The point of the guardrail is that the right thing happens whether or not you are awake. The point of the audit log is that you can verify it the next morning.
Weekly for the first month, monthly after that, and any time something material happens in the catalog (new launch, large reorder, deal event, peak season ramp). Each review answers three questions: did anything fire that should not have, did anything not fire that should have, and is the rule still calibrated to the current state of the business.