Chad Rubin
May 26, 2026 · 14 min read
Operator notes by email
Short, opinionated takes on AI agents, Amazon PPC, pricing, and inventory. No fluff. About once a week.

When I show a brand owner what an agent actually does on their Amazon account, the first thing out of their mouth is usually some version of "we already have automation." They are not wrong. They have something. The problem is the word. Automation got stretched to cover three completely different categories of software, and most operators are using one word for tools that operate on three different planets.
Here is the cleanest way I have found to explain it. There are three levels of Amazon software in 2026. A thermometer tells you the temperature. A thermostat reacts to it. An estate manager runs the building.
Each one solves a different problem. Each one fails in a different way. And most of the pain I see on seven and eight-figure Amazon accounts comes from operators trying to solve a Level 3 problem with a Level 1 or Level 2 tool.
If you can place every piece of software in your stack on this ladder, you can finally answer the question that matters: which decisions am I still making by hand, and why.
## Key takeaways >- Dashboards (Level 1) tell you what changed. They do not act. Useful, but not automation.- Rules-based automation (Level 2) is an if/then machine. It reacts to one metric and is blind to context.- Agentic AI (Level 3) weighs goals, tradeoffs, inventory, margin, rank, and risk before it acts.- A rule reacts to a metric. An agent manages the tradeoff.- Amazon is the wrong place for static if/then rules because every lever moves the others.- "We already have automation" usually means "we already have a thermostat." It is not the same product.- The right question for any vendor: can it explain why it acted, and does it escalate edge cases.
A thermometer is a reporting tool. Helium 10, Jungle Scout, Sellerboard, Data Dive, the native Seller Central reports. They show you what happened. ACoS went up. Sessions dropped. Buy Box share moved. Inventory is bleeding.
This is the original layer of the Amazon software stack, and it is still useful. Operators need a clear picture of what changed, on what SKU, in what timeframe. A good dashboard compresses a thousand rows of data into something a human can scan in under a minute.
But a thermometer does not act. It tells you the room is 88 degrees. It does not turn anything on. The work, every decision about what to do with that 88 degrees, still lives inside the operator's head.
This is where most Amazon brands have been stuck for a decade. The dashboards got prettier. The exports got faster. The number of operators required to turn data into decisions stayed exactly the same. You can buy a better thermometer every year and your team still has to run the building.
Dashboards still have a role. They are how humans audit what the agents below them are doing. But if your "automation" stops at reporting, you do not have automation. You have a screen.
From reading to action
If the framework above sounds familiar, your Amazon account is probably carrying the same drag. Apply and we will show what Marko, Oracle, and Bruno would change in your first week.

Ran a 7-figure Amazon brand for a decade. Founded Skubana (acquired). Co-founded Prosper Show. 15+ years on Amazon.
Join the brands that replaced agencies and tools with AI employees.
A thermostat is the first real piece of automation. It reads one metric and triggers one action. If the room is over 75 degrees, turn the AC on. If ACoS is over 35%, lower the bid by 10%. If conversion drops below 4%, pause the campaign.
This is what most Amazon PPC tools have been selling as AI for the last five years. Bid rules. Dayparting rules. Budget rules. Negative keyword rules. They are useful in narrow situations and they are dangerously oversold in every other situation.
Rules-based software follows instructions. Agentic AI pursues outcomes. That is the whole gap in one sentence.
The thermostat has two structural problems on Amazon. The first is that it only reads one input. ACoS is over 35%, lower the bid. It does not know that the keyword is your top brand defense term, that your competitor just went out of stock, that your inventory is sitting at 14 days of cover, or that you raised price three days ago and conversion is still recovering. It sees one number, and it pulls one lever.
The second problem is that the rule is static. You wrote it six months ago. Amazon has moved fifty times since then. The rule has not. So you are paying a piece of software to apply yesterday's logic to today's auction, on a market that resets every hour.
A thermostat in a single room with the windows closed and the weather mild is fine. A thermostat on Amazon, where the windows are open, the weather changes hourly, and the building has five hundred rooms with different rules, is going to burn money. Not because the technology is broken. Because you used the wrong tool for the job.
A thermostat reacts to a room. An estate manager runs an entire property. They are not following an instruction set. They have a goal: keep the building comfortable, safe, profitable, and on budget. To do that, they monitor everything (temperature, humidity, occupancy, energy prices, weather forecast, equipment status), reason about tradeoffs, act inside their authority, and escalate when something is outside it.
That is exactly what an Amazon agent does. Not a chatbot bolted onto a dashboard. Not a rule with a friendlier name. An agent that runs a function (PPC, pricing, inventory, catalog) the way a senior operator would run it, if a senior operator could read every signal on the account every five minutes without sleeping.
The work cycle is the same one a good human operator runs:
Monitor. Read everything that matters in the function. For PPC, that is bids, search terms, placements, conversion, ACoS, TACoS, but also inventory levels, current price, margin, rank, and what is happening to competitors.
Reason. Weigh the goal against the constraints. Are we optimizing for profit or for rank this month? Is inventory healthy enough to spend? Did price just move? Is this spike real or temporary?
Act. Make the change inside the authority granted. Move a bid. Pause a target. Negative a search term. Shift budget between campaigns.
Escalate. When the situation is outside the authority granted, or the confidence is below threshold, raise it to a human with the context attached. Not a notification. A recommendation with a reason.
That loop is the difference between software and a workforce.
The cleanest way to understand the rules-based failure mode on Amazon is to picture a thermostat in a room with open windows on a hot day. The thermostat reads 90 degrees. It does what it was told. It blasts the AC. The compressor runs all afternoon, the electric bill triples, and the room is still 88 degrees because the windows are open.
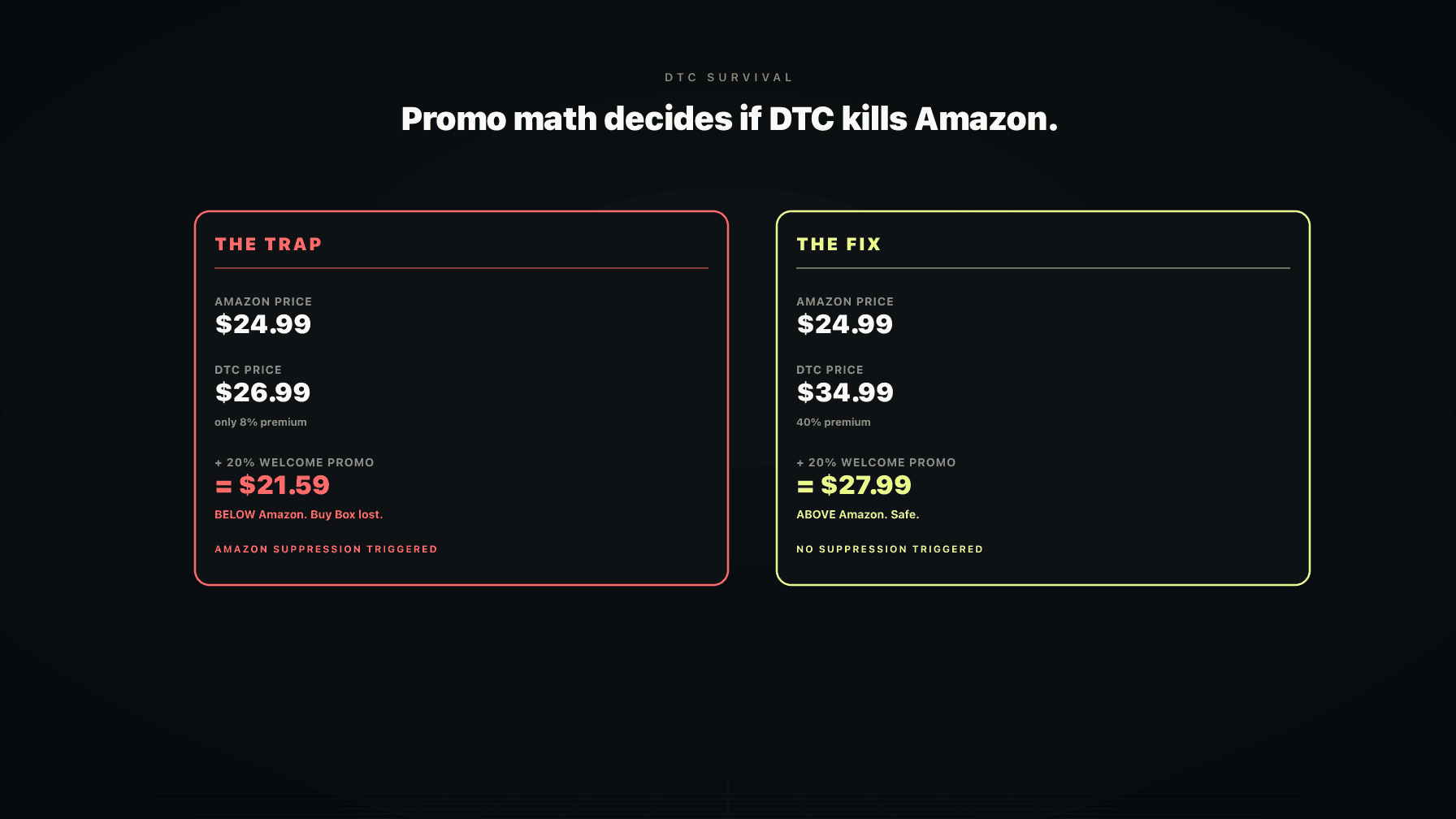
Now translate that to PPC. Your rule says: if ACoS is over 35%, lower the bid by 15%. The rule fires. The bid drops. What the rule did not see: inventory is at 11 days of cover and Amazon is about to throttle your impressions anyway. Or: you raised price 6% last week and conversion is recalibrating. Or: the keyword is your hero brand term and a competitor just went live with a coupon, so your conversion dipped for two days before it normalized.
The rule did its job. It also lit money on fire, because it solved for one variable in a system that runs on six. This is not a rare edge case. This is what rules-based PPC software does most of the time on a mature account. The wins are small and the losses are structural.
I have seen accounts where the bid management rules were technically working perfectly and the brand was bleeding margin every week. The rules were following instructions. They were not pursuing the outcome.
Here is the question list a real agent runs through before it touches a bid. Read it slowly. This is what is missing from rules-based software.
A rule answers one of those. An agent answers all of them, every time, on every SKU. A rule reacts to a metric. An agent manages the tradeoff.
That is the whole reason an agent is worth more than a rule. Not because the technology is fancier. Because the surface area of judgment is larger.
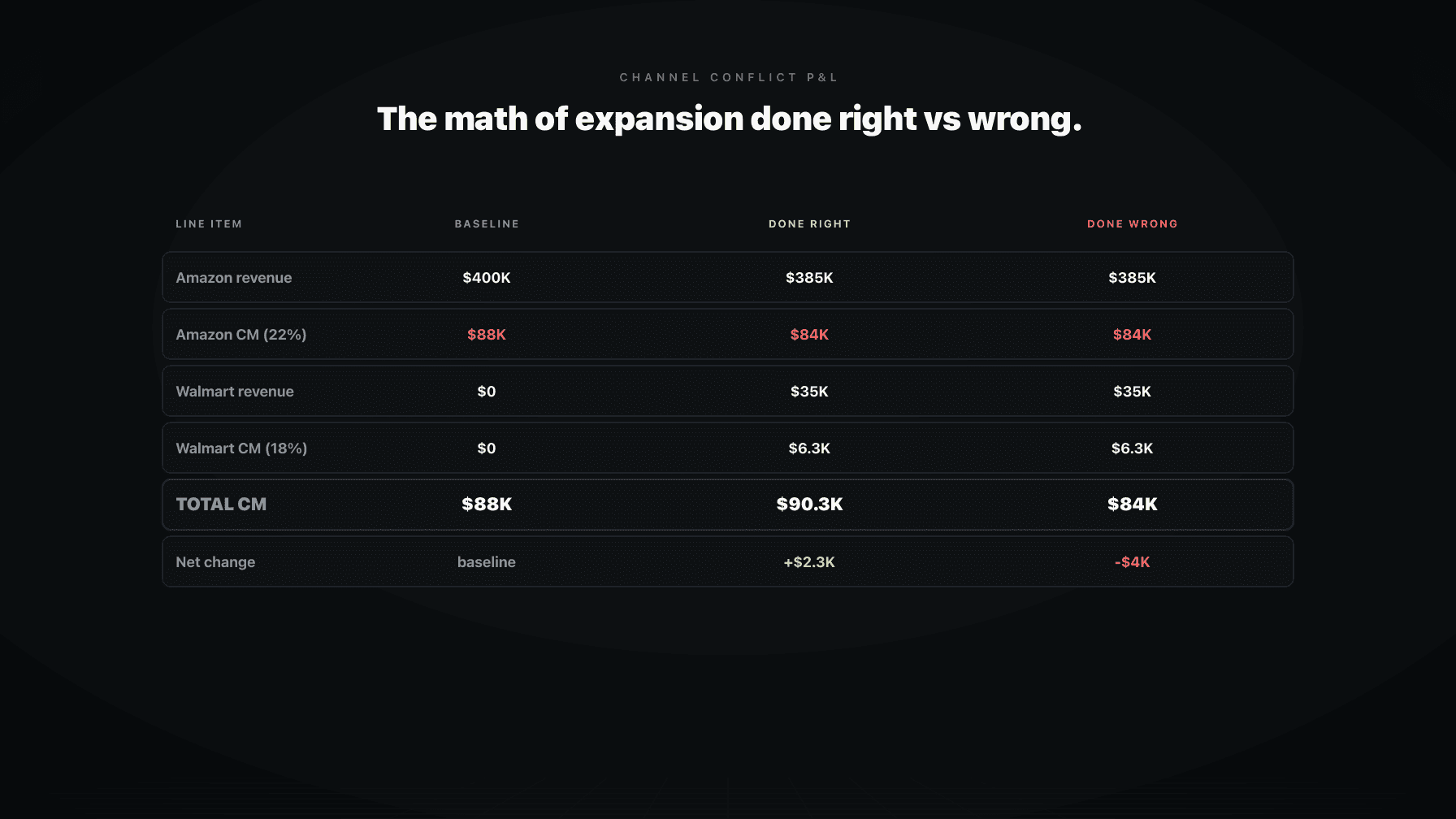
Amazon is not a room with one thermostat. It is a system where every lever moves the other levers. Raise price, conversion changes, ACoS changes, rank changes, demand shifts, inventory burn rate shifts. Lower a bid to "fix" ACoS, rank slips, sessions drop, conversion holds but units fall, days of cover stretches, you over-order on the next PO.
Anyone who has run an Amazon P&L for more than a year knows this in their gut. You cannot optimize PPC in isolation. You cannot optimize price in isolation. You cannot optimize inventory in isolation. Every move bleeds across the others.
This is the structural reason rules-based software hits a ceiling on mature accounts. Each rule lives in a silo. Bid rules in one tool. Repricing rules in another. Inventory reorder rules in a third. There is no shared context. Three tools "optimizing" simultaneously can each be right, on their own, and collectively wrong for the P&L.
Old PPC software is a dashboard. Rules-based PPC software is an if/then machine. Agentic AI is an operator. The operator looks at all of it at once.
This is why the AI Operating System framing matters. The unit is not the rule or the report. The unit is the agent, and the agents share context across functions so the moves stop fighting each other.
The fear that comes up in every demo is the same: if the agent can act on its own, am I losing control of my account? The answer is the opposite of what most operators expect.
An agent is not a replacement for the operator. It is an extension of the operator. Head plus Bot. The human sets the goal, the guardrails, the budget, and the authority. The agent runs the loop inside those boundaries and reports back. When something is outside the boundaries, it does not act. It escalates.
A good agent makes the operator more powerful, not less involved. The operator stops doing the work that a senior analyst would do (reading the data, weighing the tradeoff, executing the change) and starts doing the work that only a principal can do (setting strategy, approving exceptions, deciding when to push and when to defend).
That is what "AI workforce" actually means. Not unmanned software. Managed agents, each with a job description, each running their function, each escalating to a human when judgment is required outside their training.
If you take one thing from this post into your next vendor call, take this list. Three questions tell you exactly which level a "AI" tool is sitting at.
1. Does it weigh context across systems before it acts? Ask: "Before this tool changes a bid, what does it know about my inventory, my price, my margin, and my rank?" If the answer is "it looks at ACoS and conversion," you are looking at a thermostat with a marketing rebrand. If the answer is a structured list of inputs from across the account, you are looking at an agent.
2. Can it explain why it acted? Ask: "Show me a recent change this tool made and walk me through the reasoning." A rule cannot explain itself, it can only show you the rule that fired. An agent can show you the question list it ran, the tradeoff it weighed, and the action it picked. If the answer is a log of triggers, you have a thermostat.
3. Does it escalate edge cases instead of forcing a decision? Ask: "When the tool is not confident, what happens?" Rules-based software always acts because rules always fire. An agent has a threshold and a path. Below the threshold, it surfaces the decision to a human with context attached. That escalation behavior is the single fastest tell.
If a vendor cannot answer those three in plain language, you are not buying agentic AI. You are buying a thermostat with a new sticker.
Software runs. A workforce decides. The word matters because it sets the expectation of what the buyer is paying for.
When you hire a PPC manager, you are not buying their hands. You are buying their judgment. The decision about which keyword to defend this week, which placement to lean into, when to escalate a price test. The hands are the cheap part. The judgment is the expensive part.
Old-stack Amazon software sold the hands. It moved bids. It built reports. It changed prices. The judgment stayed inside the operator. That is fine when you have three SKUs. It collapses when you have three hundred.
An AI workforce sells the judgment. Each agent has a function (PPC, pricing, inventory, catalog), a goal, a permission set, and an escalation path. They report to the human operator the way a junior team would, except they run their function continuously instead of forty hours a week.
This is also why the unit matters for accountability. You can fire a workforce member that is not performing. You can promote one that is. You can shift their authority up or down. That is a relationship, not a feature list.
The cleanest example of what I am describing lives inside Marko, our agentic AI PPC manager. Marko does not run on if/then rules. Marko runs the monitor, reason, act, escalate loop on every campaign, every cycle.
Before Marko changes a bid on a hero ASIN, the loop looks like this. He pulls the campaign performance, the search term data, and the placement data, same as any PPC tool would. Then he pulls the inventory position. Then he pulls the current price and any pricing changes in the last 14 days. Then he pulls the margin after fees, ads, and returns. Then he checks whether the term is a defended brand keyword. Then he weighs the campaign goal that was approved by the operator (profit vs rank vs launch).
If everything lines up, he acts. If something is off (inventory is too thin, price just moved, margin is below floor, the term is one we have flagged), he holds the change and surfaces it to the human with the reason attached. Not "ACoS exceeded threshold." A sentence: "ACoS is 41% but inventory is at 12 days of cover and price moved 4% last week. Recommend holding the bid until conversion stabilizes."
That is the difference. A rule would have moved the bid. An agent asks whether the move makes sense for the P&L, not for the metric.
The same loop runs in Oracle on pricing, Bruno on inventory, and Brett on catalog. The agents share context. That coordination is what unlocks Level 3, and it is exactly what no thermostat can do.
We built Profasee as an AI workforce, not as software with an AI label glued on top. Each agent runs a function. Each agent runs the monitor, reason, act, escalate loop. Each agent shares context with the others so the moves stop fighting each other.
Marko runs PPC the way a senior media buyer would, with inventory and margin context built in, not bolted on.
Oracle runs pricing against the demand curve, the competitor set, and the margin floor, not against a static repricing rule.
Bruno runs demand planning and reorder timing with PPC spend and price elasticity in the same picture.
Brett audits listings continuously and flags issues before they cost rank, not after.
The reason it works is not the individual agents. It is that they coordinate. The PPC agent does not move a bid without checking the inventory agent. The pricing agent does not move a price without checking the demand and margin context. That cross-system reasoning is the actual product. It is also the thing rules-based software structurally cannot do, no matter how many rules you stack.
If you want to see the loop run against your own account, apply here. If you want to see how the agents are priced, pricing is here.
Rules-based automation follows instructions. You write an if/then rule, it fires when the condition is met, it takes the predefined action. It reads one metric and pulls one lever. Agentic AI pursues an outcome. It monitors many inputs, reasons about tradeoffs, acts inside an authority boundary, and escalates when it is outside that boundary. A rule reacts to a metric. An agent manages the tradeoff.
Most Amazon PPC software sold in 2026 is still rules-based, regardless of how it is marketed. The fastest way to check is to ask the vendor what the tool considers before it changes a bid. If the answer is one or two ad metrics, it is a thermostat. If the answer is a structured list including inventory, price, margin, rank, and brand defense status, it is closer to agentic.
Yes, in narrow situations. Dayparting on a stable campaign, hard budget caps, and simple negative keyword harvesting all work fine as rules. The problem is using rules for the decisions that require judgment: bid changes on hero ASINs, brand defense, launch campaigns, anything where context across systems matters. Rules can handle the easy 20%. They cannot handle the 80% that drives the P&L.
At a minimum: what is the goal for this campaign or SKU this month, what is current inventory and days of cover, what is current price and recent price movement, what is margin after all fees, is this a defended keyword, is the performance signal a real trend or noise, did a competitor change behavior recently, and is the proposed action inside my authority or does it require human approval. If the tool cannot articulate answers to those, it is not an agent.
It is the work cycle a senior human operator runs continuously. Monitor: read everything that matters in the function. Reason: weigh the goal against the constraints. Act: make the change inside your authority. Escalate: when the situation is outside your authority or confidence is low, raise it to a human with the context attached. An agent runs that loop on every SKU, every cycle, the way a person would if they never slept.
Three questions. Does it weigh context across systems before acting (not just within its own function). Can it explain why it acted in plain language, not just show you which rule fired. Does it escalate edge cases instead of forcing a decision. If the vendor stumbles on any of the three, you are buying a thermostat with a new sticker on it.
Because every lever moves the other levers. Bid changes affect rank, rank affects sessions, sessions affect conversion, conversion affects ACoS, ACoS feeds the bid rule. Price changes affect conversion and ad efficiency. Inventory affects everything. A static rule optimizes one variable in a system that runs on six. It will be right on the metric and wrong on the P&L, repeatedly, in ways that are hard to see until the quarter closes.